什么是大语言模型的幻觉?
大语言模型在处理自然语言时,有时候会出现”幻觉“现象。所谓幻觉,就是模型生成的内容与事实或上下文不一致的问题。这些问题会严重影响AI应用的可靠性和实用性。
幻觉的两大类型
事实性幻觉
指模型生成的内容与实际事实不匹配。比如在回答”第一个登上月球的人是谁?”这个问题时:
- 错误回答: “Charles Lindbergh在1951年月球任务中第一个登上月球”
- 正确事实: Neil Armstrong才是第一个登上月球的人(1969年阿波罗11号任务)
这种幻觉之所以危险,是因为模型生成的内容看起来很可信,但实际上完全错误。
忠实性幻觉
指模型生成的内容与提供的上下文不一致。这种幻觉可以分为三类:
- 输出与原文不一致(编出原文中没有的信息)
- 上下文之间不一致(前后矛盾)
- 逻辑链不一致(推理过程存在漏洞)
比如在总结新闻时,模型可能会添加原文中不存在的细节,或者前后描述矛盾。
为什么会产生幻觉?
大语言模型产生幻觉的原因主要来自三个方面:
- 数据源导致的幻觉
- 训练数据中的质量问题
- 数据中存在的错误信息
- 数据覆盖范围有限
- 训练过程导致的幻觉
- 架构限制:无法准确理解长文本的上下文关联
- 累积错误:生成过程中的错误会逐步传递和放大
- 推理相关的幻觉
- 回答过于简略
- 生成过程中的不完整推理
如何评估幻觉问题
为了客观评估模型的幻觉问题,我们可以使用多种方法:
- 事实一致性评估:将生成内容与权威来源进行比对
- 分类器评估:使用专门训练的模型来检测是否存在幻觉
- 问答测量:通过问答来验证生成内容的一致性
- 不确定度分析:评估模型对自身输出的确信程度
- 提示测量:让模型自我评估,通过特定提示策略来评估生成内容
RAG解决方案
RAG是什么?
RAG(Retrieval-Augmented Generation)也叫检索增强生成,是指对大语言模型输出进行优化,使其能够参考并利用数据源之外的权威知识。简单来说,RAG就是从外部检索对应的知识内容,和用户的提问一起构成Prompt发给大模型,再让大模型生成内容。
它的核心思想是:
- 从外部知识库检索相关信息
- 将检索到的信息作为上下文提供给模型
- 让模型基于这些上下文生成回答
简单来说:RAG = 外部知识检索 + Prompt构建 + LLM 生成
为什么需要RAG?
LLM虽然是一个强大的工具,但它本身拒绝了解任何时事,且它给出的答案总是非常流畅,内容却不一定靠谱。这存在几个主要的问题:
- LLM的训练数据量有限且无法更新到最新知识。
- 当用户需要专业或领域特定的数据时,LLM往往缺乏相应的知识
- 对于答案的问答内容很难从源创进行溯源
- 由于技术限制,不同的训练源使用相同的大语言技术,可能会产生不确信的响应
而RAG为解决这些问题带来了以下优势:
- 经济高效:预训练和微调模型的成本很高,而RAG是一种经济高效的新方法
- 信息时效:使用RAG可以为LLM提供最新的研究、统计数据或新闻
- 增强用户信任度:RAG允许LLM通过来源归属来呈现具体的信息,输出可以包括对来源的引文或参考,这可以增加对对话的生成式人工智能解决方案的任何信心
RAG是如何工作的?
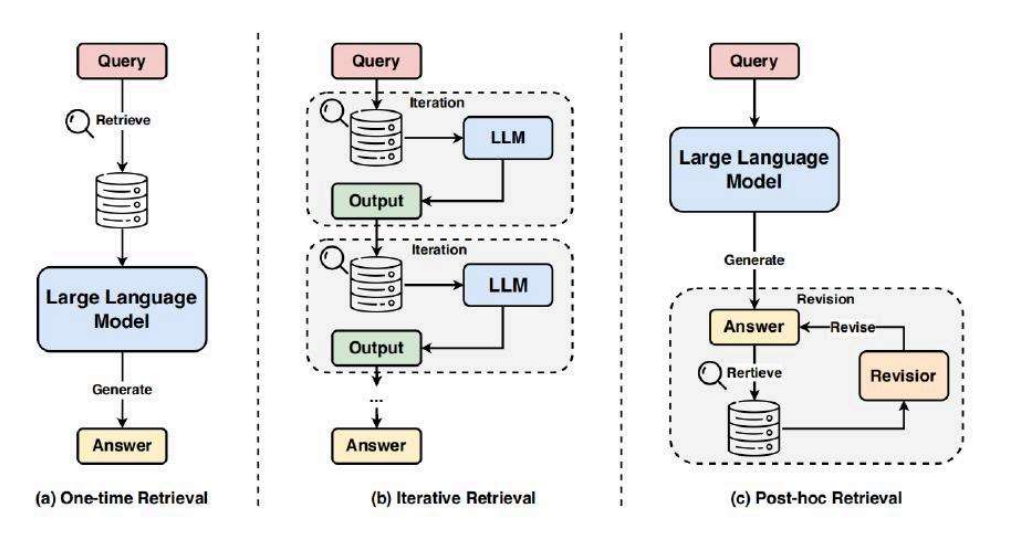
RAG采用三种主要的检索方式:
- 一次性检索:
- 从单次检索中获取相关知识
- 直接预置到大模型的提示词中
- 不会收集反馈信息
- 迭代检索:
- 允许在对话过程中多次检索
- 每一轮都可能有新的检索
- 支持多轮对话优化
- 事后检索:
- 先生成答案
- 然后检索验证
- 对答案进行修正
RAG实战示例
以一个简单的问答场景为例,展示RAG的实际应用流程:
- 用户提问:”公司有销售什么产品?”
- 系统处理流程:
- 使用检索器获取产品相关文档
- 将文档内容与问题组合成提示词
- 通过LLM生成回答
- 确保回答基于检索到的事实信息
- 最终输出:包含准确的产品信息,并且所有信息都可以溯源。
AI应用开发利器:向量数据库详解
什么是向量数据库?
向量数据库(Vector Database)是一种专门用于存储和处理向量数据的数据库系统。它不同于传统的关系型数据库,因为它需要将所有数据映射为特定的向量格式,并采用相似性搜索作为主要的检索方式。
一个生动的例子:识别猫咪
让我们通过一个识别猫咪的例子来理解向量数据库。假设我们有一组不同品种的猫咪图片:
- 波斯猫
- 英国短毛猫
- 暹罗猫
- 布偶猫
- 无毛猫
每张猫咪图片都可以用一组数字向量来表示其特征,如:
波斯猫: [0.4, 0.3, 0.4, 0.5, 0.3, 0.4, 0.5, ...]
英国短毛猫: [0.7, 0.2, 0.5, 0.5, 0.5, 0.5, 0.5, ...]
暹罗猫: [0.5, 0.3, 0.4, 0.5, 0.3, 0.4, 0.5, ...]
这些数字代表了猫咪的各种特征,比如:
- 毛发长度
- 体型大小
- 面部特征
- 耳朵形状等等
向量数据库的优势
与传统的数据库相比,向量数据库有以下特点:
- 数据类型:
- 传统数据库:数值、字符串、时间等结构化数据
- 向量数据库:向量数据(不存储原始数据,有的也支持)
- 数据规模:
- 传统数据库:小,1亿条数据对关系型数据库来说规模很大
- 向量数据库:大,最少千亿数据是基线
- 数据组织方式:
- 传统数据库:基于表格、按照行和列组织
- 向量数据库:基于向量、按向量维度组织
- 查找方式:
- 传统数据库:精确查找/范围查找
- 向量数据库:近似查找,查询结果是与输入向量最相似的向量
相似性搜索算法
在向量数据库中,支持通过多种方式来计算两个向量的相似度:
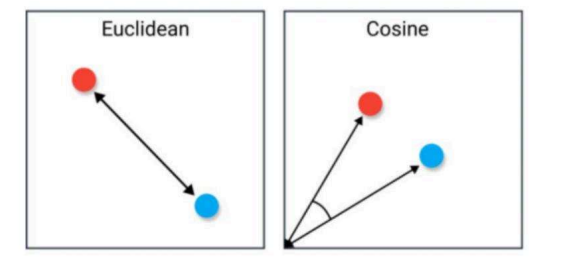
余弦相似度:主要是用于衡量向量在方向上的相似性,特别适用于文本、图像和高维空间中的向量。它不受向量长度的影响,只考虑方向的相似程度,计算公式如下(计算两个向量间的夹角的余弦值,取值范围为[-1, 1]):
similarity(A,B) = (A·B)/(||A||·||B||)
欧式距离:主要是用于衡量向量之间的直线距离,得到的值可能很大,最小为0,通常用于低维空间或需要考虑向量各个维度之间差异的情况。欧式距离较小的向量被认为更相似,计算公式如下:
distance(A,B) = √∑(Ai-Bi)²
例如下图:左侧就是欧式距离,右侧就是余弦相似度。
实际应用场景
向量数据库的主要应用场景包括:
- 人脸识别
- 图像搜索
- 音频识别
- 智能推荐系统
这些场景的共同特点是:需要对非结构化数据(如图片、文本、音频)进行相似度搜索。
在RAG中,我们会将文档的知识按特定规则分成小块,转换成向量存储到向量数据库中。当人类提问时,我们将问题转换为向量,在数据库中找到最相似的文本块,这些文本块可以成为Prompt的补充内容。
深入理解Embedding嵌入技术
Embedding 是什么?
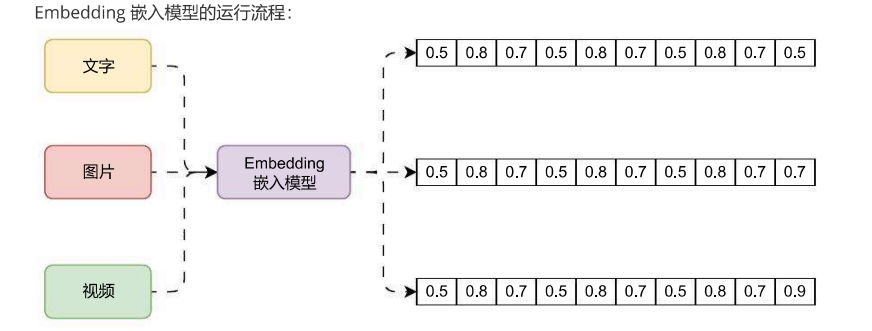
Embedding(嵌入)是一种在机器学习中广泛使用的技术,它能将文本、图片、视频等非结构化数据映射到向量空间中。一个Embedding向量通常是一个包含N个浮点数的数组,这个向量不仅表示了数据的特征,更重要的是通过学习可以表达它们的内在语义。简而言之,Embedding就是一个模型生成方法,可以将非结构化的数据,例如文本/图片/视频等数据映射成有意义的向量数据。比如一段文本、一张图片、一段视频,警告Embedding模型处理后都会变成类似这样的向量:
[0.5, 0.8, 0.7, 0.5, 0.8, 0.7, 0.5, 0.8, 0.7, 0.5]
主流的Embedding模型
目前主要有这几类Embedding模型:
- Word2Vec(词嵌入模型)
- 通过学习词语转化为连续的向量表示
- 基于两种主要算法:
CBOW和Skip-gram - 能够捕捉词语之间的语义关系
- 1GloVe
- 类似Word2Vec但采用不同的训练方式
- 同时考虑全局共现信息
- 能较好地保存词语间的语义关系
- 适用于多种自然语言处理任务
- FastText
- 考虑了单词的子词信息
- 能处理训练集中未出现的生词
- 支持多语言处理
- 大模型Embeddings
- 如OpenAI的text-embedding-ada-002
- 输入维度8191个tokens
- 输出维度1536维向量
Embedding的神奇之处
Embedding最有趣的特性是它能够捕捉语义关系。让我们看一个著名的例子
King - Man + Woman ≈ Queen
(国王 - 男人 + 女人 ≈ 女王)
这个公式展示了Embedding不仅仅是把词语转换成数字,它还能:
- 保留词语之间的关系
- 支持向量运算
- 产生有意义的结果
我们可以通过可视化的方式看到这些词语在向量空间中的分布:
- woman和girl的向量位置接近
- man和boy的向量位置接近
- king和queen虽然性别不同,但都位于表示”统治者”的维度上
Embedding的重要价值
- 降维:将高维数据映射到低维空间,大大降低了计算复杂度
- 捕捉语义信息:不仅能记录表面的词频信息,还能捕捉深层的语义关联
- 泛化性:Embedding学习到的是通用的语言表达方式,可以应用到新的场景
- 泛化能力:对于未见过的数据,也能基于已学习的语义特征给出合理的向量表示
- 可视化支持:虽然Embedding本身很复杂,但我们可以使用t-SNE等工具将其可视化,帮助理解数据的内在结构。
在RAG中的应用
在RAG系统中,Embedding主要用于两个场景:
- 文档向量化:将知识库中的文档转换为向量
- 查询向量化:将用户的问题转换为向量
通过比较这些向量的相似度,我们可以找到与用户问题最相关的文档片段,从而提供更准确的答案。
RAG应用实战:OpenAI Embedding与LangChain的结合
OpenAI Embedding接口简介
OpenAI提供了多个Embedding模型选择,以下是几个主要模型的对比:
| 模型 | Token数(每个文档800个) | 性能评估 | 最大输入 | 向量维度 |
|---|---|---|---|---|
| text-embedding-3-small | 62,500 | 62.3% | 8191 | 1536 |
| text-embedding-3-large | 9,615 | 64.6% | 8191 | 3072 |
| text-embedding-ada-002 | 12,500 | 61.0% | 8191 | 1536 |
LangChain中的Embedding组件使用
在LangChain中,Embedding类提供了统一的接口来使用各种嵌入模型:
class Embeddings(ABC):
"""Interface for embedding models."""
@abstractmethod
def embed_documents(self, texts: List[str]) -> List[List[float]]:
"""Embed search docs."""
@abstractmethod
def embed_query(self, text: str) -> List[float]:
"""Embed query text."""
使用示例:
import dotenv
import numpy as np
from langchain_openai import OpenAIEmbeddings
from numpy.linalg import norm
# 初始化Embedding模型
embeddings = OpenAIEmbeddings()
# 进行文本嵌入
query_vector = embeddings.embed_query("你好, 我是小潘")
documents_vector = embeddings.embed_documents([
"你好, 我是小潘",
"这个自然语言处理的人叫小潘",
"来知若惘, 既心若旷"
])
# 计算相似度
def cosine_similarity(vector1, vector2):
dot_product = np.dot(vector1, vector2)
norm1 = norm(vector1)
norm2 = norm(vector2)
return dot_product / (norm1 * norm2)
CacheBackEmbedding的使用
为了提高性能,LangChain提供了缓存功能:
from langchain.embeddings import CacheBackedEmbeddings
from langchain.storage import LocalFileStore
embeddings = OpenAIEmbeddings(model="text-embedding-3-small")
embeddings_with_cache = CacheBackedEmbeddings.from_bytes_store(
embeddings,
LocalFileStore("./cache/"),
namespace=embeddings.model,
query_embedding_cache=True
)
使用缓存时需要注意:
- underlying_embedder: 使用的基础嵌入模型
- document_embedding_cache: 用于缓存文档的存储结构
- batch_size: 可选参数,默认None
- namespace: 用于文档缓存的命名空间
- query_embedding_cache: 是否缓存查询向量
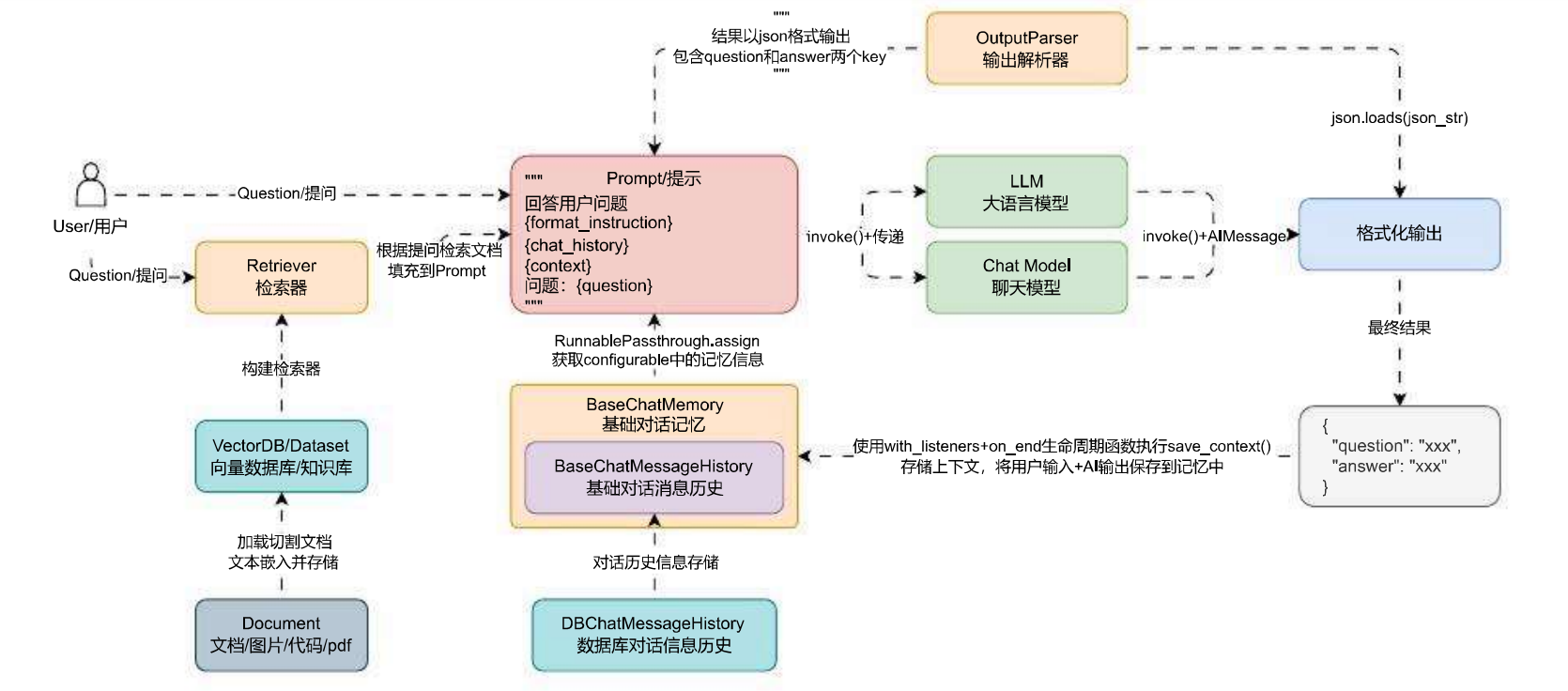
运行流程分析
一个完整的RAG应用运行流程如下:
- 文档预处理
- 分割文档
- 生成向量
- 存入向量数据库
- 查询处理
- 将用户问题转为向量
- 在向量数据库中检索
- 组合上下文生成回答
- 缓存优化
- 缓存常见文档的向量
- 缓存常见查询的向量
- 提供响应速度
注意事项
- 向量维度的选择
- 需要平衡精度和效率
- 维度越高,表达能力越强,但计算成本也越高
- 缓存策略
- 合理设置缓存大小
- 选择适当的缓存淘汰策略
- 定期更新缓存
- 性能优化
- 使用批处理提高效率
- 合理使用多线程
- 监控资源使用情况
