前言
在当今的AI应用开发中,检索增强生成(Retrieval-Augmented Generation, RAG)已经成为一种重要的技术范式。它通过将大语言模型与外部知识库结合,极大地提升了AI系统的知识获取能力和输出质量。而LangChain作为一个强大的框架,为RAG应用的开发提供了丰富的组件支持。本文将深入剖析LangChain中RAG应用开发的核心组件,帮助你更好地理解和使用这些工具。
核心组件概览
在开始深入学习之前,我们先来了解LangChain中RAG应用开发涉及的主要组件:
- Document组件与文档加载器 - 负责文档的加载和基础处理
- 文档转换器与分割器 - 处理文档转换和分块
- VectorStore组件 - 实现向量存储和检索
- Blob相关组件 - 处理二进制大对象数据
Document 组件与文档加载器详解
Document 组件基础
Document 是 LangChain 的核心组件之一,它定义了一个通用的文档结构,包含两个基本要素:
Document = page_content(页面内容) + metadata(元数据)
这种结构允许我们统一处理各种类型的文档,同时保留文档的元信息。
文档加载器类型
LangChain 提供了多种文档加载器:
- 通用文本加载器
- CSV文件加载器
- HTML网页加载器
- PDF文档加载器
- Markdown文档加载器
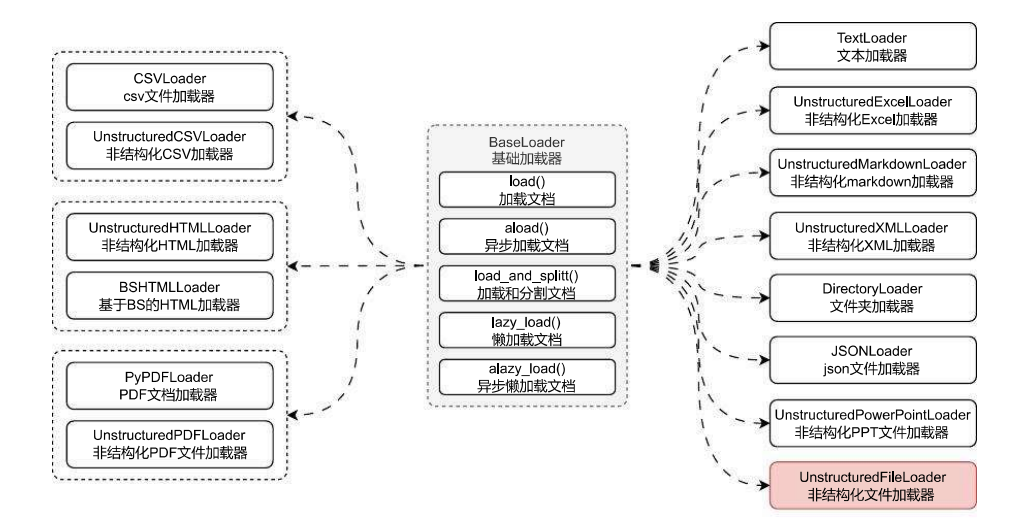
每种加载器都专门处理特定类型的文档,但它们都会将文档转换成统一的Document格式。
from langchain_community.document_loaders import TextLoader
# 加载文本文件示例
loader = TextLoader("./data.txt", encoding="utf-8")
documents = loader.load()
异步加载支持
对于大型文档,LangChain提供了异步加载方式:
async def load_documents():
async with aiofiles.open(file_path, encoding="utf-8") as f:
# 异步处理文档
yield Document(
page_content=line,
metadata={"source": file_path}
)
文档转换器与分割器
DocumentTransformer 组件
文档转换器用于处理以下常见问题:
- 文档太大导致的性能问题
- 原始文档格式不符合要求
- 文档内容需要标准化处理
文档转换器的工作原理
DocumentTransformer组件的主要职责是对文档进行各种转换操作,包括:
- 文档切割
- 文档层级提取
- 文档翻译
- HTML标签处理
- 重排等多个功能
在LangChain中,所有文档转换器都继承自BaseDocumentTransformer基类,它提供了两个核心方法:
class BaseDocumentTransformer:
def transform_documents(self):
# 转换文档列表
pass
async def atransform_documents(self):
# 异步转换处理
pass
文档分割器详解
字符分割器(CharacterTextSplitter)
CharacterTextSplitter 是基础的分割器,它有以下重要参数:
separator: 分割符,默认为’\n\n’chunk_size: 每块文本的最大大小,默认4000chunk_overlap: 块与块之间的重叠大小,默认200length_function: 计算文本长度的函数,默认lenkeep_separator: 是否在分割的块中保留分隔符
使用示例:
from langchain_text_splitters import CharacterTextSplitter
text_splitter = CharacterTextSplitter(
separator="\n\n",
chunk_size=500,
chunk_overlap=50,
add_start_index=True
)
# 使用分割器处理文档
splits = text_splitter.split_documents(documents)
实践建议
在实际应用中,有以下几点建议:
- 选择合适的chunk_size
- 太大会影响处理效率
- 太小可能破坏语义完整性
- 建议根据实际需求在400-1000之间调整
- 合理设置overlap
- 设置适当的重叠可以保持上下文连贯
- 通常设置为chunk_size的10%-20%
- 注意分隔符的选择
- 根据文档类型选择合适的分隔符
- 可以使用多级分隔符策略
VectorStore组件与检索器
VectorStore基础概念
VectorStore组件负责:
- 存储文档的向量表示
- 提供相似性检索功能
- 支持不同的向量检索策略
检索器的使用
LangChain 提供了多种检索策略:
from langchain import VectorStore
# 基础相似性检索
results = vectorstore.similarity_search(query)
# 带相似度分数的检索
results = vectorstore.similarity_search_with_score(query)
# MMR检索策略
results = vectorstore.max_marginal_relevance_search(query)
VectorStore实现细节
支持的向量数据库
- Chroma
- FAISS
- Pinecone
- Milvus
检索策略详解
- 相似度检索(Similarity Search)
- 基于余弦相似度
- 支持Top-K检索
- MMR检索(Maximum Marginal Relevance)
- 平衡相关性和多样性
- 可配置lambda参数调整权重
- 混合检索策略
- 关键词+语义检索
- 支持自定义评分函数
Blob与BlobParser组件
Blob方案介绍
Blob是LangChain处理二进制数据的解决方案,它具有以下特点:
- 支持存储字节流数据
- 提供统一的数据访问接口
- 灵活的元数据管理
基本使用示例:
from langchain_core.document_loaders import Blob
from langchain_core.document_loaders.base import BaseBlobParser
# 创建Blob对象
blob = Blob.from_path("./data.txt")
# 使用解析器
parser = CustomParser()
documents = list(parser.lazy_parse(blob))
Blob数据存储类详解
LangChain中的Blob数据存储提供了丰富的属性和方法,让我们详细了解一下:
核心属性
- data: 原始数据,支持存储字节,字符串数据
- mimetype: 文件的mimetype类型
- encoding: 文件的编码,默认utf-8
- path: 文件的原始路径
- metadata: 存储的元数据,通常包含source字段
常用方法
# 字符串转换
as_string(): # 将数据转换为字符串
# 字节转换
as_bytes(): # 将数据转换为字节数据
# 字节流操作
as_bytes_io(): # 将数据转换为字节流
# 从路径加载
from_path(): # 从文件路径加载Blob数据
# 从原始数据加载
from_data(): # 从原始数据加载Blob数据
BlobLoader实现
BlobLoader是一个抽象接口,用于实现二进制数据的加载。以下是一个自定义BlobLoader的示例:
from langchain_core.document_loaders import Blob
from langchain_core.document_loaders.base import BaseBlobParser
class CustomBlobLoader(ABC):
"""自定义Blob加载器实现"""
@abstractmethod
def yield_blobs(
self,
) -> Iterable[Blob]:
"""加载并返回Blob数据流"""
def __init__(self, file_path: str):
self.file_path = file_path
def lazy_load(self):
"""延迟加载实现"""
for blob in self.yield_blobs():
yield Document(
page_content=blob.as_string(),
metadata={"source": blob.source}
)
通用加载器使用最佳实践
GenericLoader是LangChain提供的一个通用加载器,它结合了BlobLoader和BaseBlobParser的功能:
from langchain_community.document_loaders.generic import GenericLoader
# 创建通用加载器
loader = GenericLoader.from_filesystem(
"./", # 文件系统路径
glob="*.txt", # 文件匹配模式
show_progress=True # 显示进度
)
# 使用加载器
for idx, doc in enumerate(loader.lazy_load()):
print(f"当前加载第{idx + 1}个文件, 文件信息:{doc.metadata}")
性能优化建议
- 使用延迟加载
- 对于大文件优先使用lazy_load()
- 避免一次性加载全部内容
- 合理配置缓存
- 利用缓存减少重复加载
- 及时清理不需要的缓存
- 错误处理
- 实现适当的错误处理机制
- 记录加载过程中的异常
- 进度监控
- 对大规模数据处理添加进度显示
- 实现断点续传机制

